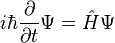Newton's Method
An usual slogan that we hear in the agile community is
continuous improvement. A cycle of of
inspection of problems and
adaptations to solve them, optimizing incrementally and in an restless manner.
When I was introduced to the concept,
@toledorodrigo used an analogy that I really like:
Imagine the problem of finding the roots of an continuous function. For simple equations its usually trivial to find them analytically, but as the function gets more and more complex it becomes harder and some times impossible to get an analytically precise solution.
But here is where the
Newton method comes along with the iterative method described below:
- choose an starting X value.
- trace the tangent of the function.
- Find the root of that tangent.
- Use the new X value and repeat step 2.
The similarity with continuous improvement became clear when we point out the step of tracing the tangent as an inspection phase, where we guess in which direction we should search for the solution, and the discovery of the new candidate as the adaptation phase.
Monte-Carlo Method
This analogy got me wondering about another iterative method which is also used when the analytical solution is to complex to get, and that is the
Monte Carlo method.
In this method we are also using a lot of guessing, in fact a lot more guessing, but the first fundamental difference is that it is not governed by a local property such as the derivative at the current candidate. Normally we randomize in a global manner and look for global properties.
I got in touch with the Monte Carlo method while in graduation where a college of mine used it in a complex problem. He had N particles interacting with each other, which gave an O(N^2) complexity in each frame, and that is a lot of work! The Monte Carlo Method came in where he (and many others) used small random perturbations to the system (adaptation) and measured if a global property of it was better or worse and accepting the change if it passed that test (inspection). In this case the test was the total energy of the system which had to became smaller and smaller.
The amount of change that was made in each iteration was proportional to the given temperature of the system. And a common method used in those kinds of simulations or even in experimental cases was raising and lowering the temperature in cycles, which helps the system to relax and don't stop in a local minimum, and get to the "optimal" state.
The beauty of the algorithm is that the randomness makes the step by step variations seem counter intuitive, things don't move the way they seem the should be moving, giving our mental biased perspective.
Also notice a critical difference about the presented Monte Carlo method. The phases of inspection and adaptation are swapped, we first adapt to only then inspect, and only if the changes are any good to the global system they are accepted. Is this a silly algorithm? Maybe, but it's also similar to a very popular algorithm that is running for millions of years in a sustainable manner, which is in the core Darwin's theory, the survival of the fittest. Apparently nature likes to variate and inspect afterwards, killing the genes that don't improve the global property of staying alive.
Conclusion
Although I only have a bit more then 3 years of experience working with teams, I have noticed that many of important changes came almost by chance, of course that well thought and planed improvements occur, that's us humans doing our part. But it seems this is another subject in agile that needs to be balanced, and the natural part of mutate our genes are neglected. To me the
Agile Manifesto phrase "Responding to change over following a plan" is taking a hole new perspective, and not only responding we should also create disturbances so that we don't get stuck in following a plan.